
Creating presentation materials requires complex multimodal reasoning skills to summarize key concepts and arrange them in a logical and visually pleasing manner. Can machines learn to emulate this laborious process? We present a novel task and approach for document-to-slide generation. Solving this involves document summarization, image and text retrieval, and slide structure to arrange key elements in a form suitable for presentation. We propose a hierarchical sequence-to-sequence approach to tackle our task in an end-to-end manner. Our approach exploits the inherent structures within documents and slides and incorporates paraphrasing and layout prediction modules to generate slides. To help accelerate research in this domain, we release a dataset of about 6K paired documents and slide decks used in our experiments. We show that our approach outperforms strong baselines and produces slides with rich content and aligned imagery.
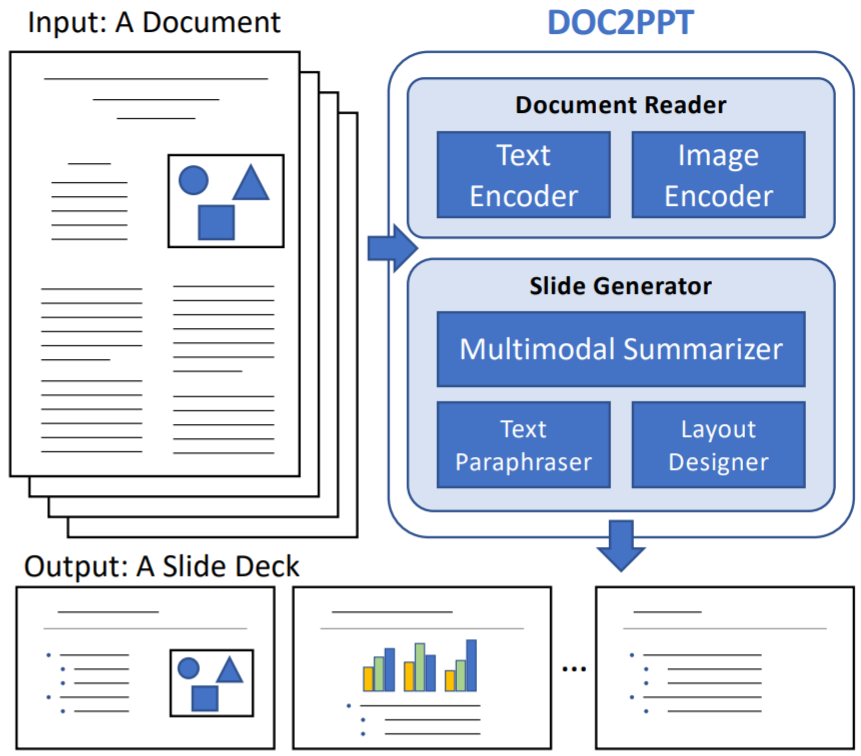
We introduce a novel task of generating a slide deck froma document. This requires solving several challenges in the vision & language domain, e.g., visual-semantic embedding and multi-modal summarization. In addition, slides exhibit unique properties such as concise text (bullet points) and stylized layout. We propose an approach to solving DOC2PPT, tackling these challenges.
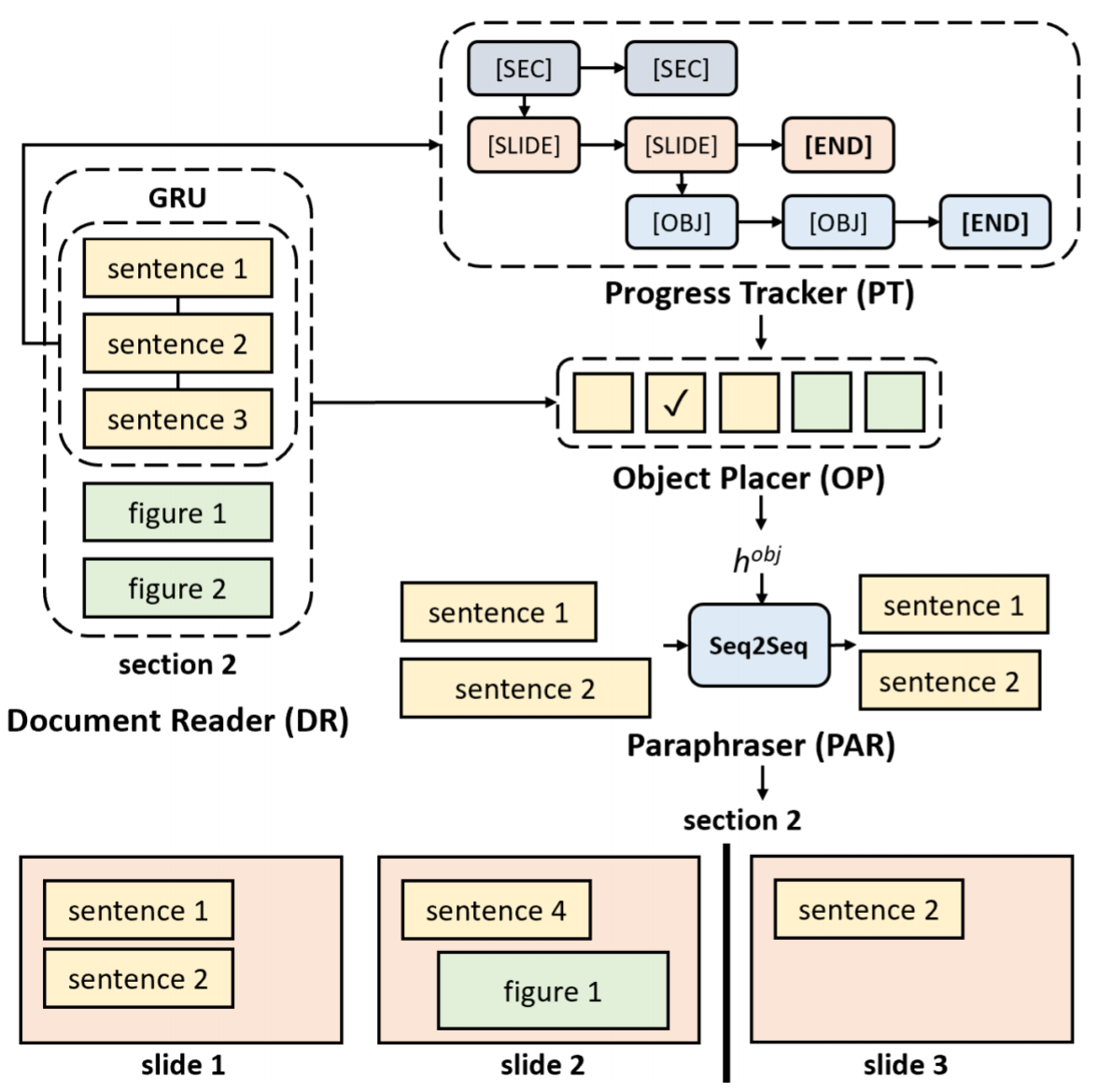
DOC2PPT involves “reading” a document (i.e., encoding sentences and images) and summarizing it, paraphrasing the summarized sentences into a concise format suitable for slide presentation, and placing the chosen text and figures to appropriate locations in the output slides.
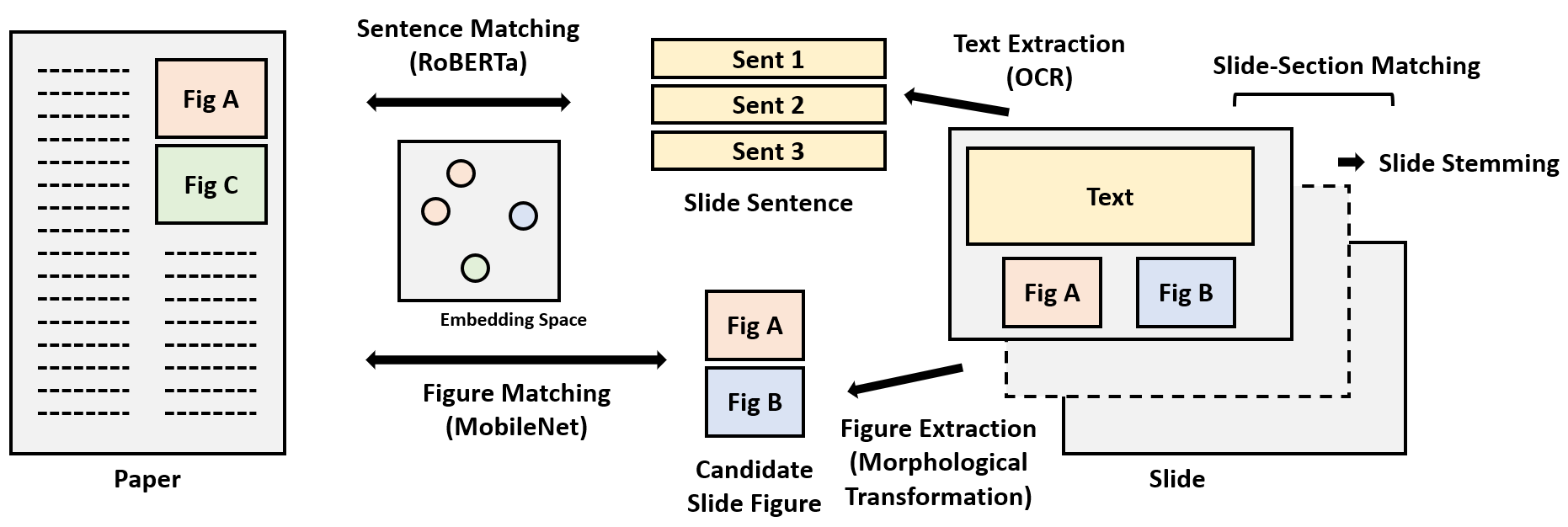
We collect pairs of documents and the corresponding slide decks from academic proceedings. Our dataset contains PDF documents and slides in the JPEG image format. For the training and validation set, we automatically extract text and figures from them and perform matching to create document-to-slide correspon-dences at various levels. To ensure that our test set is clean and reliable, we use Amazon Mechanical Turk (AMT) and have humans perform image extraction and matching for the entire test set.